Prepared by: Helena M. Garcia, University of North Carolina at Chapel Hill and Kathryn Foster, Cornell University
Date: June 2026
Original Authors: Helena M. Garcia, Antonia Sebastian, Kieran P. Fitzmaurice, Miyuki Hino, Elyssa L. Collins, Gregory W. Characklis
Specific purpose of code:
The code provides an example of how to generate flood extent data, modeled after the process used to create the North Carolina Flood Extent Archive dataset. Due to privacy restrictions from the National Flood Insurance Program (NFIP), the address-level records used to create NC-FLDEX, a full code cannot be shared. However, an example code is shared using randomly generated NFIP claims and policy locations from the NC Building Footprint 2010 data. The event dates for the code align with Hurricane Florence (2018). The purpose of the example code is 1) to represent how NC-FLDEX was developed, and 2) to provide a guide for replicating similar products for different geographies.
The North Carolina Flood Extent Archive (NC-FLDEX) example code creates flood exent raster data. The rasters represent binary flood extents (1= likely flooded) and are created using random forest models trained on high-resolution geospatial predictors and address-level National Flood Insurance Program (NFIP) claims and policy data. NFIP claims locations are labeled as flood presence points and policy locations without claims are labeled as flood absence points. The flood presence and absence points are then used to estimate flood probabilities at every 30-meter cell in the study area. The NC-FLDEX example code includes a comparison of model outputs with publicly available physics-based and remote sensing-based model outputs for Hurricane Florence. The archive example code also includes North Carolina building footprint data to support building-level exposure summaries.
General Application:
This code can be adapted to estimate flood extent in other locations and different time frames that are relevant to aging populations. It can also be combined with other relevant spatial datasets to examine historical flooding events to compare exposure across events.
How does or could this code allow researchers to assess research questions related to aging or life course?:
The spatial 30m NC-FLDEX raster data can be spatially aggregated to demographic units (e.g., census tracts, block groups) and linked with datasets containing age or health-related variables.
Data sets used:
- Population, socioeconomic, or health data: US Census Bureau Primary and Secondary Roads, US Census Bureau Census Tracts 2010, US Zip Code Tabulation Areas (ZCTAs) 2000, and North Carolina Building Footprints
- Climate, weather, disaster or environment data: Address-level NFIP Claims, NFIP Redacted Claims and Policies, USGS 30m Elevation, NLCD Fractional Impervious Surface, ERA5 Hourly Precipitation, NHD Coastline, NC OneMap Major Hydrography, Height Above Nearest Drainage (HAND), Soil Hydraulic Conductivity (ksat), and FEMA Special Flood Hazard Area (SFHA)
Are all the data publicly available or are some restricted-access?
The address-level NFIP claims are restricted-access data.
Links to data:
US Census Bureau Primary and Secondary Roads:
https://www.fema.gov/openfema-data-page/fima-nfip-redacted-policies-v2
USGS 30m Elevation: https://data.usgs.gov/datacatalog/data/USGS:35f9c4d4-b113-4c8d-8691-47c428c29a5b
NLCD Fractional Impervious Surface: https://www.sciencebase.gov/catalog/item/655ceb8ad34ee4b6e05cc51a
ERA5 Hourly Precipitation: https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels?tab=overview
NHD Coastline: https://www.usgs.gov/national-hydrography/national-hydrography-dataset
NC OneMap Major Hydrography: https://www.nconemap.gov/datasets/nconemap::major-hydrography-streams-rivers/about
Height Above Nearest Drainage (HAND): https://www.hydroshare.org/resource/73aaa3efcda2465ba6227f535400f36b/
Soil Hydraulic Conductivity (ksat): https://websoilsurvey.nrcs.usda.gov/app/
FEMA Special Flood Hazard Area (SFHA): https://www.nconemap.gov/maps/a178aae74ee347d786e853e5a442eea2/explore?location=35.121157%2C-79.918650%2C7.86
Coding Language: R was used to create these data, more information and example codes are available in the dataverse repository.
Tools and Packages used: Dplyr, sp, raster, tigris, ggplot2, sf, readxl, writexl, nngeo, lubridate, stringr, tidyr, raster, ggplot2, reshape2, data.table, randomForest, stats,ranger, caret, tuneRanger, mlr, stringr, pROC, ROCR, dismo
Output(s): Dataset and mapping
Spatial extent: Flood extent rasters span the coastal draining USGS HUC-6 watersheds within North Carolina (030101, 030102, 030201, 030202, 030203, 030300, 030401, 030402). The study area overlaps with 78 of North Carolina’s 100 counties. A shapefile of the study area is included in repository.
Temporal extent: The 78 flood events included in NC-FLDEX are based on National Flood Insurance Program damage records from 1/1/1996 to 9/30/2020.
Published papers that use this code:
Garcia, H. M., Sebastian, A., Fitzmaurice, K. P., Hino, M., Collins, E. L., & Characklis, G. W. (2025). Reconstructing repetitive flood exposure across 78 events from 1996 to 2020 in North Carolina, USA. Earth’s Future, 13, e2025EF006026. https://doi.org/10.1029/2025EF006026
Joyce Pak, Bradford E. Jackson, Shabbar I. Ranapurwala, Miyuki Hino, Lawrence S. Engel, Katherine E. Reeder-Hayes, Jillian L. Evans-Strong, Jennifer L. Lund; Impacts of Hurricane-Related Flooding on Time to Initial Cancer Directed Treatment in North Carolina. Cancer Epidemiol Biomarkers Prev 2026; https://doi.org/10.1158/1055-9965.EPI-25-1664
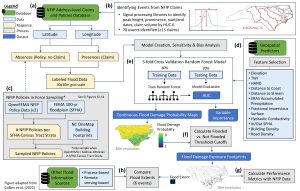
Graphic reproduced from Garcia et al (2025) published in Earth’s Future.